
O N8N vem ganhando espaço na internet recentemente por ser open-source, e por dar liberdade de fazer automações que antes eram mais difícil com outras ferramentas do mesmo segmento, ou que só podia ser feito por código. O N8N trás conexões com +500 serviços, o que lhe dá uma grande versatilidade de ferramentas, para os mais variados tipos de propósitos.
Para demonstrar tal coisa, nós da Data Trends, decidios fazer um projeto ELT que será dividido em duas partes devido o tamanho do mesmo, e para ficar de fácil entendiemento.
Essa primeira parte, irá comtemplar a parte da automação responsável por fazer a cópia do dado, isto é, extrair o dado da fonte, nesse caso, do banco Postgres, e copiá-lo para o destino em formato JSON. Nosso destino aqui será o MinIo.
Antes de tudo, iremos falar sobre a configuração do seu ambiente para podermos colocar esse incrível projeto no ar. Então garanta que você tenha o Docker instalado na sua máquina e funcionando, pois ele será nossa base para tudo.
Configurando projeto…
Escolha uma pasta para trabalhar, com seu o seu terminal aberto nessa respectiva pasta, rode o comando:
git clone https://github.com/marllonDev/n8n-automation.gitEsse código, irá baixar o nosso projeto do GitHub. Agora que você baixou o projeto, ainda temos que fazer umas coisas para você conseguir rodar esse projeto.
Primeiro de tudo, crie um arquivo .env no caminho n8n-compose/. Esse arquivo não é feito o upload para o GitHub por questões de boas práticas e segurança. Então você deve criar você mesmo o seu com suas chaves.
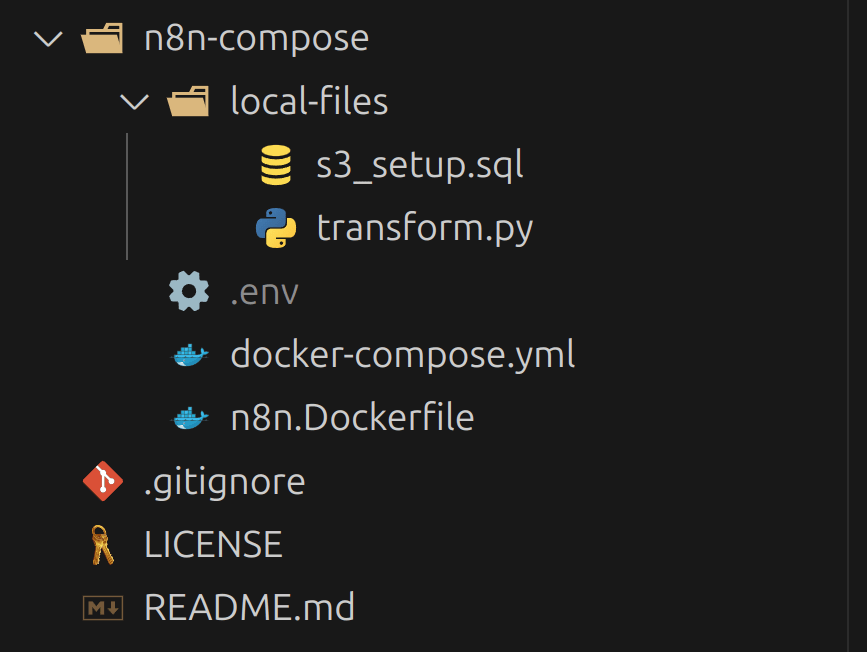
O seu arquivo .env, após criado, deve ficar na mesma estrutura de pasta ao lado. Isto é, n8n-compose/.env.
Nesse arquivo, crie as seguintes variaveis:
- N8N_ENCRYPTION_KEY=sua_chave_aqui
- Para a chave acima, no seu terminal, rode o comando:
docker exec -it n8n openssl rand -hex 32para gerar sua chave. Após gerada, cole ela no local solicitado acima. OBS: Rode esse comando após subir os serviços, que irá acontecer um pouco mais abaixo.
- Para a chave acima, no seu terminal, rode o comando:
- GENERIC_TIMEZONE=America/Sao_Paulo
- POSTGRES_USER=coloque_um_nome_de_sua_escolha_aqui
- POSTGRES_PASSWORD=coloque_uma_senha_de_sua_escolha_aqui
- MINIO_ROOT_USER=coloque_um_nome_de_sua_escolha_aqui
- MINIO_ROOT_PASSWORD=coloque_uma_senha_de_sua_escolha_aqui
- SSL_EMAIL=pode_colocar_seu_email
Isso deve ser configurado por cada pessoa, pois são informações pessoais, então é uma boa prática nunca subir isso para o GitHub. Essas variaveis de ambiente devem ser configuradas pois o arquivo docker-compose.yml irá precisar na hora de rodar o projeto.
Com o projeto baixado e configurado, navegue para dentro da pasta n8n-compose usando o código cd n8n-compose/. E então rode o comando abaixo:
docker compose up -dEsse código irá subir todos os serviços do arquivo docker-compose.yml da pasta n8n-compose. Você pode vê-los pelo terminal através do código abaixo:
docker psOu, através da interface gráfica do próprio Docker Desktop na aba de Contâiners.
Agora você pode rodar o comando para pegar a KEY do campo N8N_ENCRYPTION_KEY descrito um pouco acima.
Acessando o N8N
Para poder de fato usar o N8N, abra o link [http://localhost:5678/], e coloque as credenciais que você configurou nos passos anteriores. Irá abrir a interface gráfica do N8N. Agora, vamos importar os dois workflows criados para essa automação.
- Na página inicial, no canto superior direito, você verá um botão Create Workflow, clique nele, e crie um workflow em branco.
- No canto superior direito novamente, você verá um botão com “3 pontinhos”( … ). Clique nele e vá em Import from File. Agora basta importar os dois arquivos .json contidos no caminho /backup.
- Com os dois workflows importados, só falta as credenciais que iremos precisar.
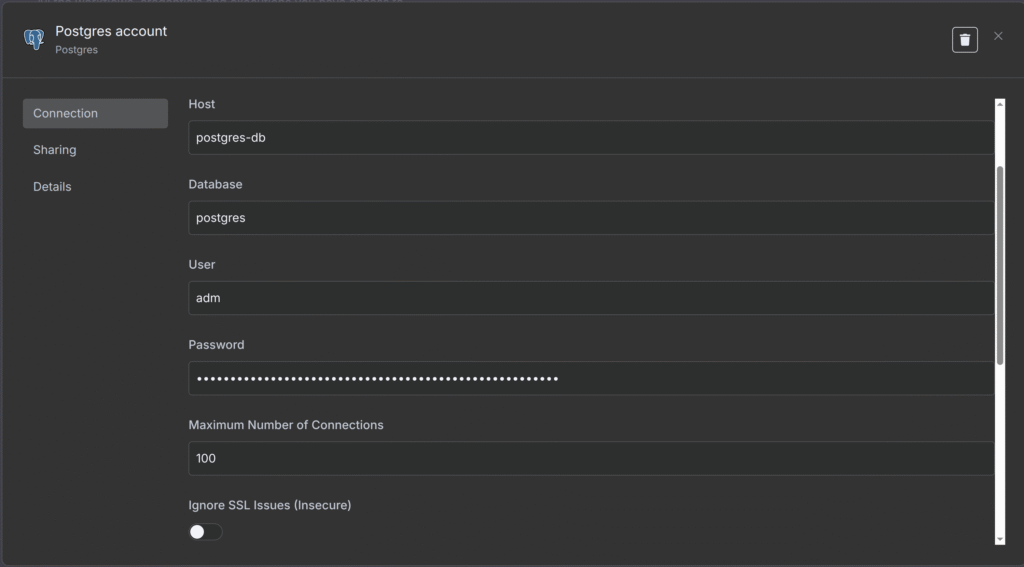
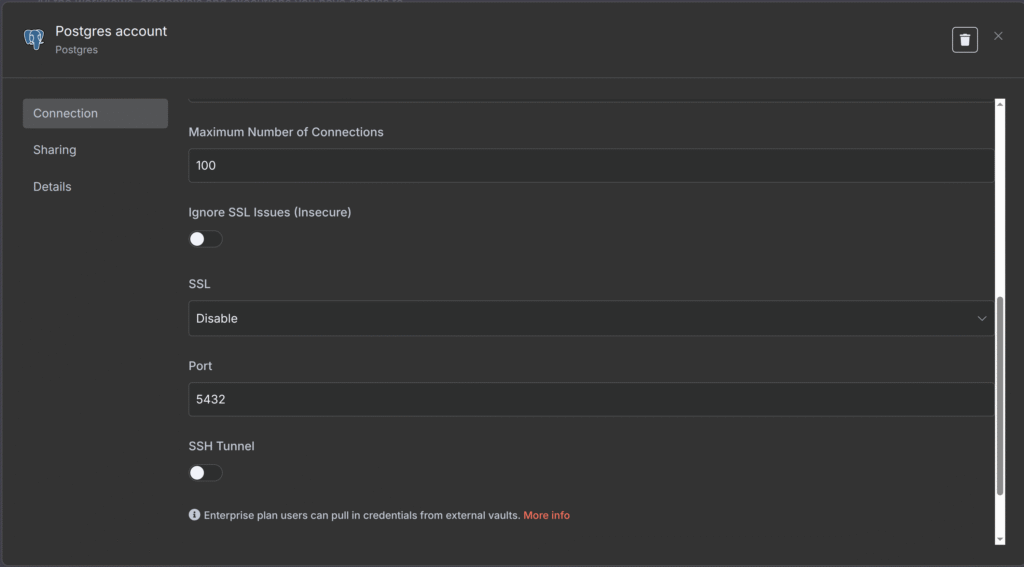
- Para a credencial do Postgres, faça como o print abaixo:
-
- Para a credencial do MinIo, faça como o print abaixo:
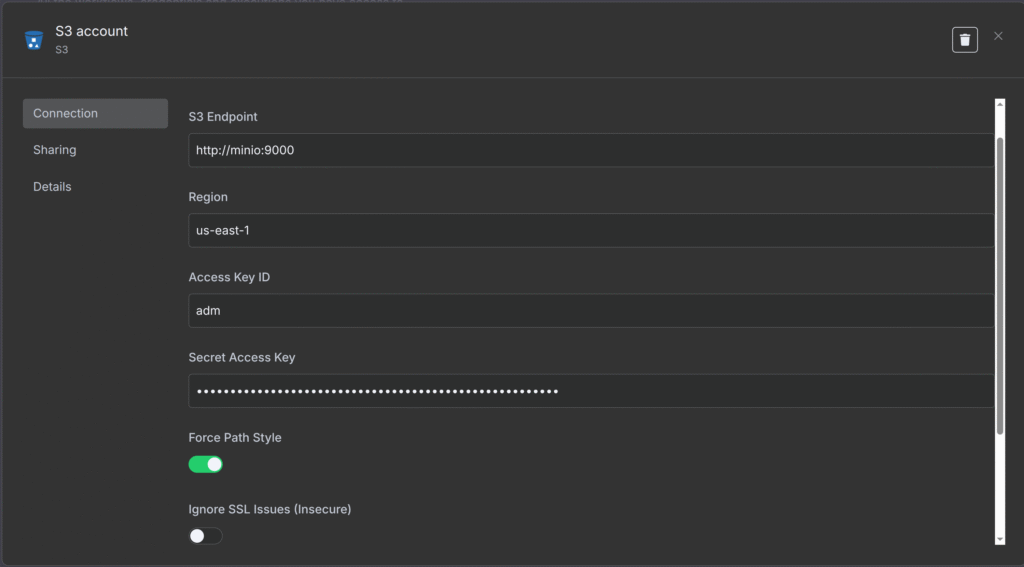
Se estiver com dúvidas onde achar as senhas de acesso, elas estão no seu arquivo .env que você configurou nos passos anteriores.
Acessando o MinIo
Agora para vamos configurar o MinIo. Aqui é bem fácil e rápido, então vamos lá!!
Acesse o link [http://localhost:9001] para abrir a versão Web do MinIo. Nele você irá se deparar com uma tela de login, coloque as mesmas credenciais do arquivo .env que você já tem configurado.
Na página incial, você verá que é bem simples e clean, então basta clicar no canto superior esquerdo no botão Create Bucket, coloque o nome processed-parquet, e depois crie outro bucket, mas agora com o nome raw-files-json. Pronto!!
Com esses dois buckets criado, nossa configuração está completamente pronto.
O Projeto
Como disse no início deste poste, essa será a primeira parte onde iremos contemplar a primeiro workflow dessa automação, o Automation for Copy Data.
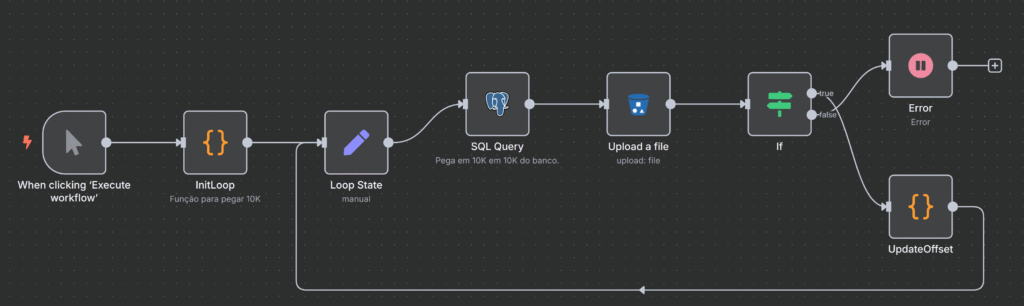
Nosso pontapé inicial, será o click do mouse, como mostra o primeiro Nó da esquerda para direita, isso dará início ao fluxo. No InitLoop, definimos um código em Java Script que defini um parâmetro chamado offset com o valor 0(zero), que na frente iremos usar. O código é o seguinte:

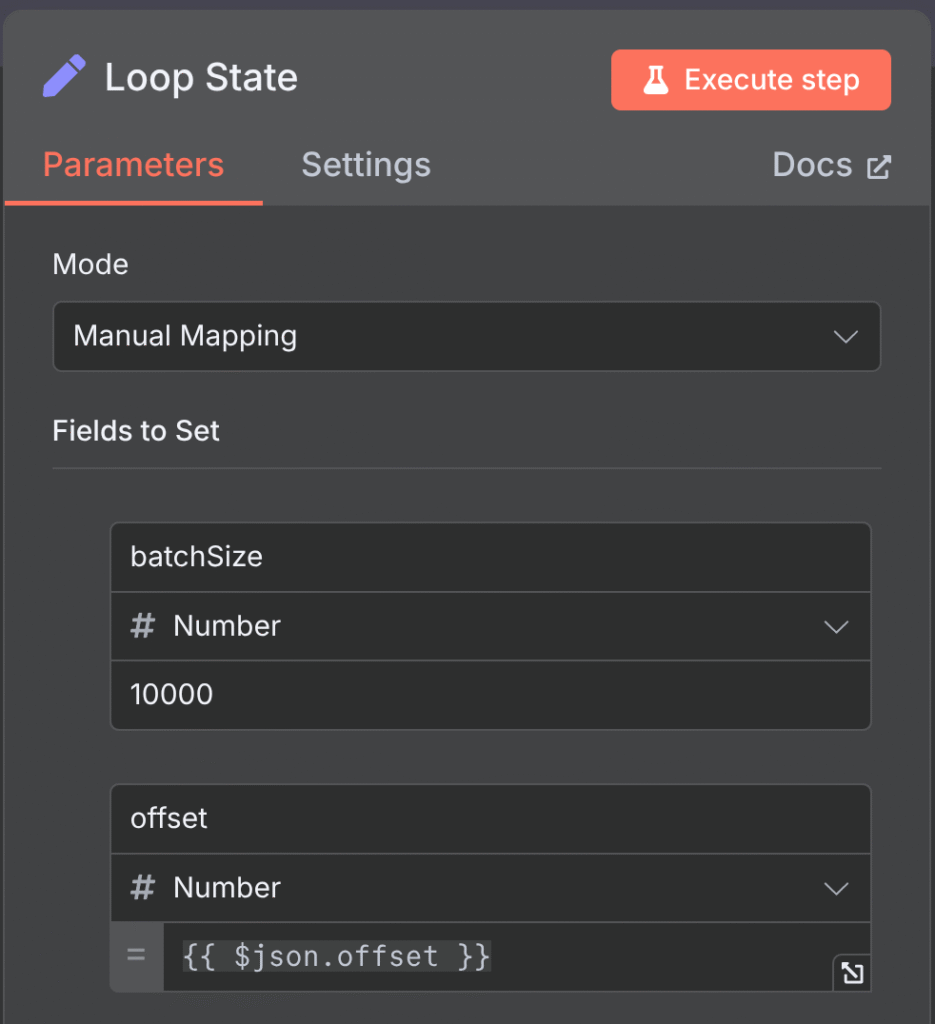
O terceiro Nó é o Loop State ao lado, ele defini um novo campo chamado batchSize cujo o valor é 10 mil e, um campo chamado offset, onde seu valor incial é 0(zero), respectivamente.
O Nó do Postgres, nós usamos o código abaixo:
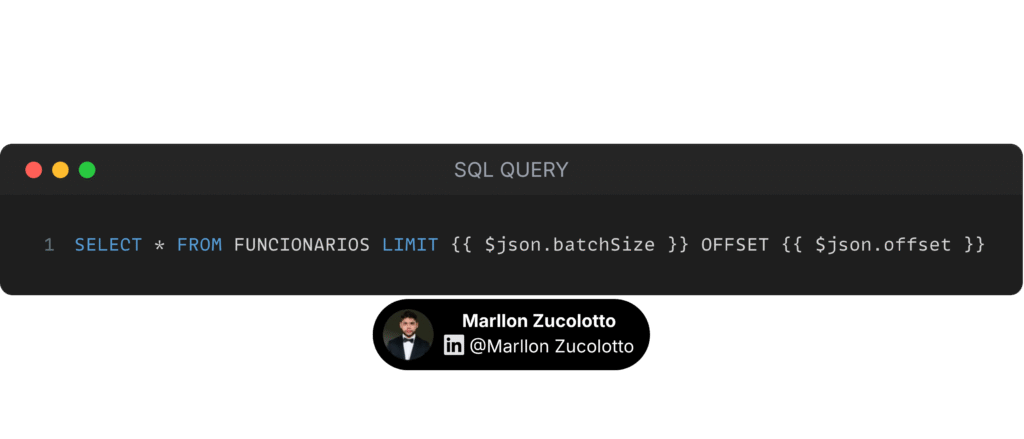
Essa query dinâmica irá buscar no banco de dados os primeiros 10 mil registros, sem pular nenhum, pois o parâmetro offset está definido como 0(zero) nesse momento.
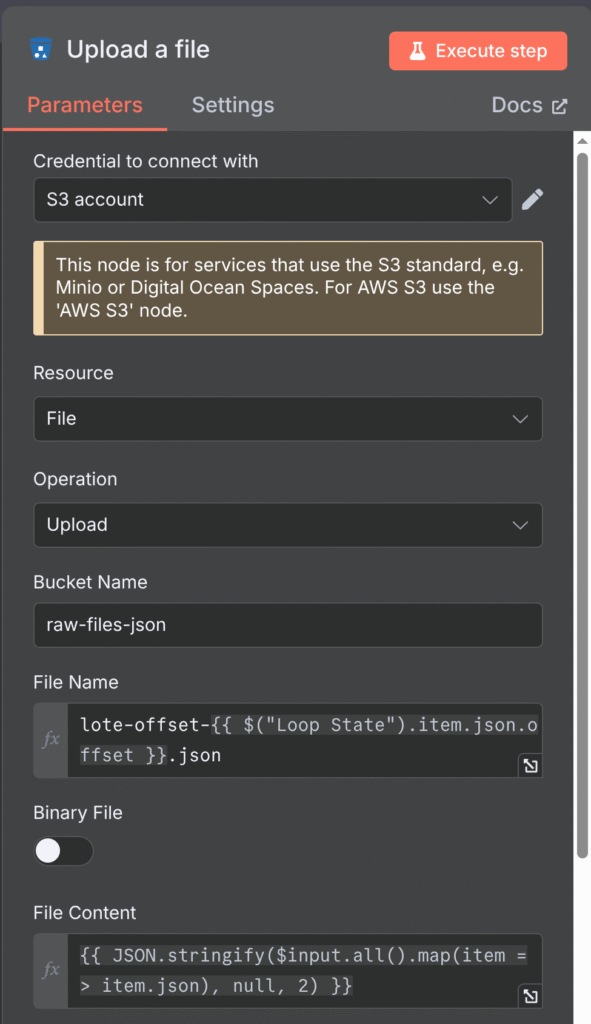
Nosso Nó do bucket S3 ou MinIo está configurado dessa forma. Perceba que ele recebe os parâmetros do Loop State no campo File Name. Foi feito dessa maneira para que cada vez que ele rodar e extrair 10 mil registros do banco, ele adicione o nome tendo coêrencia à contagem, nesse caso, de 10 mil em 10 mil. Em resumo, o nome do arquivo no bucket ficaria assim: lote-offset-10000.json. Na outra rodada seria lote-offset-20000.json, e assim sucessivamente.
Nosso penúltimo Nó, é um IF que tem a cláusula(de forma traduzida): Se o tamanho dos itens do Nó SQL Query for IGUAL ao campo BatchSize do Nó Loop State. Então, o IF é TRUE, e irá para o próximo Nó que descreveremos nos próximos parágrafos. Agora, fique com a imagem de como está nosso Nó:
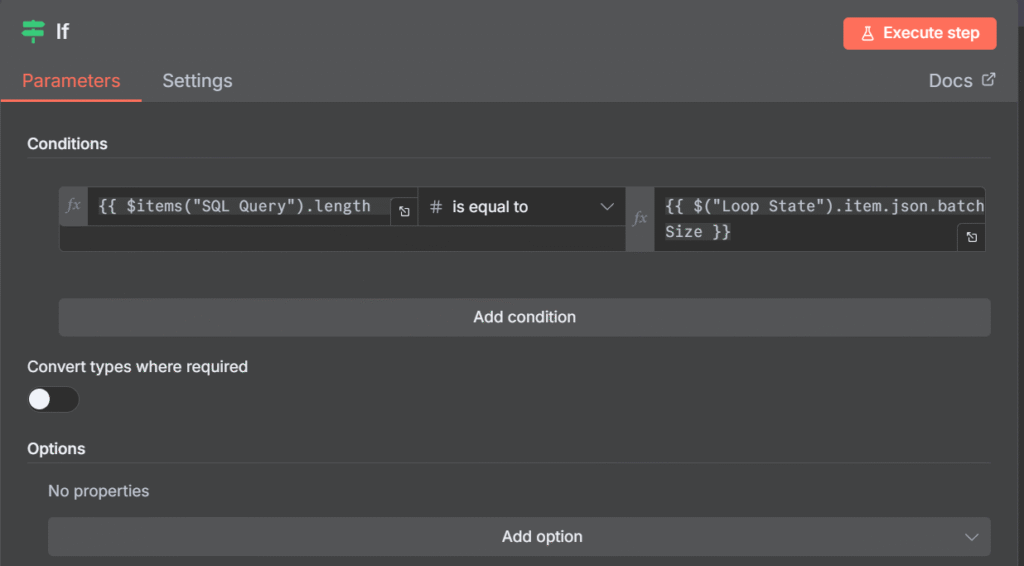
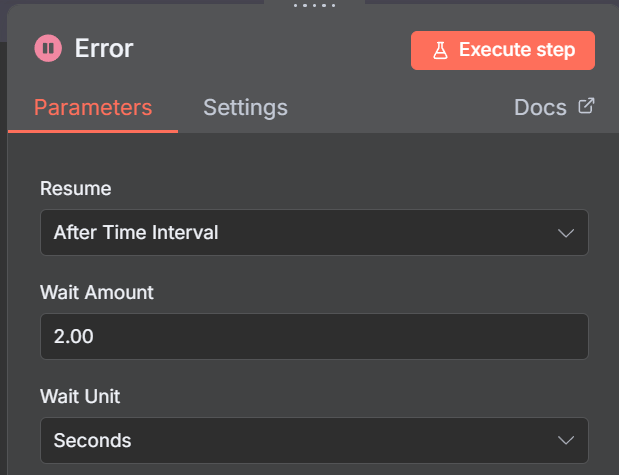
Se o Nó IF for FALSE, então ele irá para um Nó chamado Wait, que esperará 2 segundos e a automção irá parar. Veja abaixo:
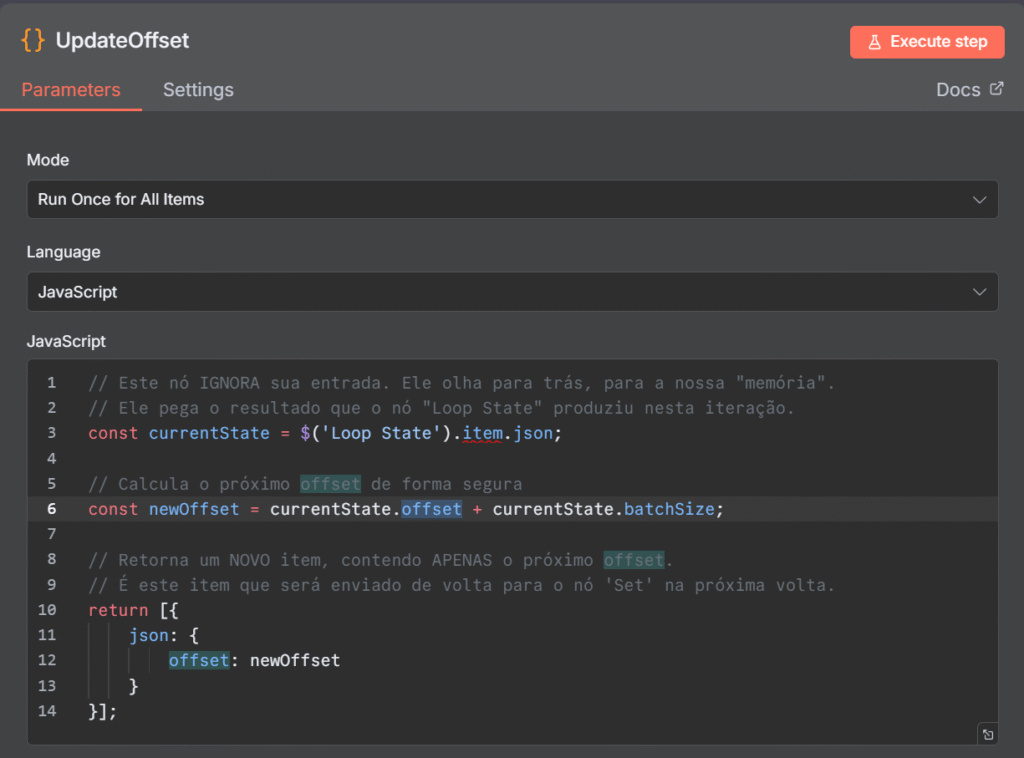
Agora, como disse anteriormente, se for TRUE, então irá para o Nó chamado UpdateOffset, onde tem um código Java Script que em resumo, diz para pegar o valor do campo offset do Nó Loop State e somar com o campo BatchSize do própro Nó Loop State novamente. Fazendo assim, a cada loop que for TRUE, o valor do campo offset ser incrementado de 10 mil em 10 mil. Você pode ver abaixo como o código foi feito:
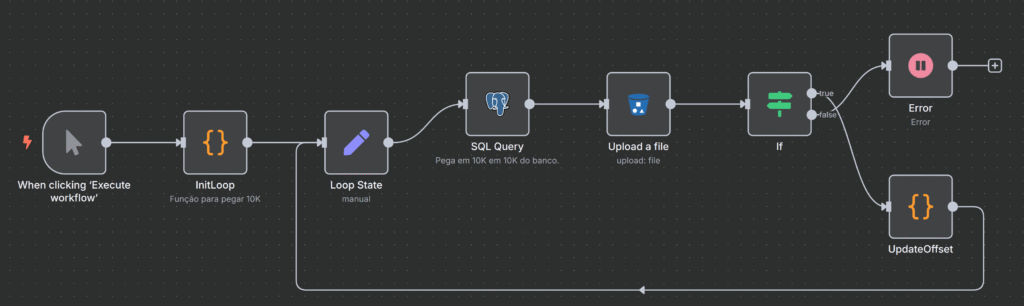
Após cada Nó ser explicado nesse guia, vou mostrar novamente uma visão Macro de toda a automação.
Conclusão
Com isso feito, eu passei por todos os Nós dessa primeira parte da automação ELT. Sei que para quem nunca viu esse tipo de coisa pode ser confuso, mas depois de fazer no seu próprio PC, e ver rodando algumas vezes, tenho certeza que ir acompanhando os Loops, irá deixar você mais a “Par”, de como está acontecendo nas entre linhas.
A segunda parte da Automação, que será a parte da tranformar o dado Raw(Cru) no formato Json para o formato Parquet, sairá em breve e irei estar deixando o link aqui nesse post.
Nos comentários abaixo, por favor, compartilhe se a automação foi bem-sucedida. Caso contrário, deixe seu comentário que estarei disponível para ajudar a resolver qualquer problema. E, se a automação foi um sucesso, fique à vontade para compartilhar seus resultados para que eu possa conhecer sua experiência com o projeto.
Compartilhe:






Publicar comentário