
Quer um ambiente pronto para codar? Bom… Hoje trago um ambiente todo em Docker com PySpark, Python3, Jupyter Notebook e um bando de dados relacional (Postgres) para os Engenheiros de plantão.
O uso do Docker tem se tornado cada vez mais popular entre engenheiros de dados, desenvolvedores e áreas correlatas, por sua capacidade de criar ambientes portáteis e consistentes. Em vez de se preocupar com as diferenças entre os ambientes de desenvolvimento, teste e produção, o Docker permite que você empacote sua aplicação e suas dependências em contêineres, que podem ser executados em qualquer lugar. Por exemplo, se você está trabalhando em uma equipe com múltiplos membros, cada um pode rodar o mesmo ambiente localmente, eliminando problemas de compatibilidade.
Além disso, o Docker oferece isolamento entre os serviços que você está executando, o que aumenta a segurança e a confiabilidade das suas aplicações. Cada contêiner é isolado e não interfere nos outros, permitindo que você execute diferentes versões da mesma aplicação ou diferentes serviços no mesmo servidor de forma segura.
Para rodar esse ambiente na sua máquina, você irá precisar do Docker e de uma IDE de sua preferência, por exemplo o VS Code ou o Trae.
1. Dockerfile
O Dockerfile é um arquivo de texto que contém todas as instruções necessárias para criar uma imagem Docker. Ele define o que a imagem deve conter e como deve ser configurada. Por exemplo, no nosso caso, estamos especificando que a imagem deve ser baseada em Python 3.10 e que deve incluir o Java OpenJDK 11, além de instalar todas as dependências necessárias para o funcionamento do PySpark. O Dockerfile é essencial para automatizar o processo de construção de imagens, garantindo que você sempre tenha um ambiente consistente.
FROM python:3.10-bullseye
# Atualiza os repositórios e instala o Java (OpenJDK 11)
RUN apt-get update && \
apt-get install -y openjdk-11-jre && \
rm -rf /var/lib/apt/lists/*
# Define JAVA_HOME
ENV JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
ENV PATH="$JAVA_HOME/bin:$PATH"
# Cria e ativa o ambiente virtual
ENV VIRTUAL_ENV=/opt/venv
RUN python -m venv $VIRTUAL_ENV
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
# Copia os arquivos de requirements
COPY requirements.txt .
# Instala as dependências Python dentro da venv
RUN pip install --upgrade pip && pip install -r requirements.txt
# Define o diretório de trabalho
WORKDIR /app
# Copia o código da aplicação
COPY . .
CMD ["jupyter", "notebook", "--ip=0.0.0.0", "--port=8888", "--allow-root", "--no-browser", "--NotebookApp.token=''"]2. requirements.txt
pyspark
psycopg2-binary
pandas
notebookEsse arquivo diz as bibliotecas que o Python irá baixar. Nesse caso, são os itens acima. É importante ressaltar que, ao utilizar bibliotecas bem definidas no arquivo requirements.txt, você garante que todas as versões de bibliotecas necessárias para o seu projeto estão documentadas, evitando problemas de compatibilidade no futuro. Além disso, você pode adicionar novas bibliotecas que achar necessárias conforme o projeto evolui, facilitando o gerenciamento de dependências.
3. docker-compose.yml
O arquivo docker-compose.yml é fundamental quando você precisa trabalhar com múltiplos serviços que interagem entre si. Neste caso, estamos criando dois contêineres: um para o aplicativo em PySpark e outro para o banco de dados PostgreSQL. O uso do Docker Compose simplifica a configuração e o gerenciamento de serviços interdependentes, permitindo que você defina todos os parâmetros necessários em um único arquivo. Isso torna o processo de inicialização de ambientes complexos muito mais simples e rápido.
version: '3.8'
services:
spark:
build: .
container_name: pyspark_app
volumes:
- .:/app
environment:
- PYSPARK_PYTHON=python
- JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
- POSTGRES_HOST=postgres
- POSTGRES_DB=postgres
- POSTGRES_USER=adm
- POSTGRES_PASSWORD=adm
depends_on:
- postgres
ports:
- "8888:8888" # Exemplo: Jupyter notebook, se quiser rodar
postgres:
image: postgres:14
container_name: postgres_db
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=adm
- POSTGRES_PASSWORD=adm
ports:
- "5432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:4. Hora de rodar
Com essas configurações feitas, basta rodar o comando docker-compose up --build. Esse comando irá demorar alguns minutos para baixar todas as dependências e construir as imagens. É importante ter paciência durante esse processo, pois uma vez que tudo estiver configurado corretamente, sua aplicação estará pronta para uso. Além disso, sempre que você fizer alterações no Dockerfile ou no docker-compose.yml, você deve rodar o comando novamente para que as alterações sejam aplicadas.
Após isso, abra o link -> http://localhost:8888. Isso abrirá o Jupyter Notebook pronto para você começar a codar. O Jupyter Notebook é uma ferramenta poderosa para trabalhar com dados, permitindo que você escreva código, visualize resultados e documente seu trabalho em um único lugar. É ideal para protótipos rápidos e experimentação com dados.
É importante se familiarizar com a interface do Jupyter, pois ela oferece diversas funcionalidades que podem facilitar seu trabalho. Por exemplo, você pode usar células de código para executar comandos em Python e células de markdown para documentar suas análises, tornando seu trabalho mais organizado e compreensível para outros.
Veja como você deve ver o Jupyter Notebook ao abrir o link:
Para fazer o primeiro teste, isto é, fazer a conexão com o banco Postgres e ver se está realmente funcionando, basta adicionar um arquivo main.ipynb como descrito abaixo. Este arquivo servirá como o ponto de partida para suas análises e testes iniciais. Além de verificar a conexão, você poderá realizar consultas e manipulações de dados diretamente do Jupyter Notebook.
main.ipynb
CMD 1
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("PySparkPostgres") \
.config("spark.jars.packages", "org.postgresql:postgresql:42.3.1") \
.getOrCreate()
df = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql://postgres:5432/postgres") \
.option("dbtable", "funcionarios.app_test") \
.option("user", "adm") \
.option("password", "adm") \
.option("driver", "org.postgresql.Driver") \
.load()
df.show()CMD 2
df.createOrReplaceTempView("app_test")
procurar_nome = spark.sql("SELECT NOME FROM app_test WHERE NOME = 'Marllon' ")
procurar_nome.show()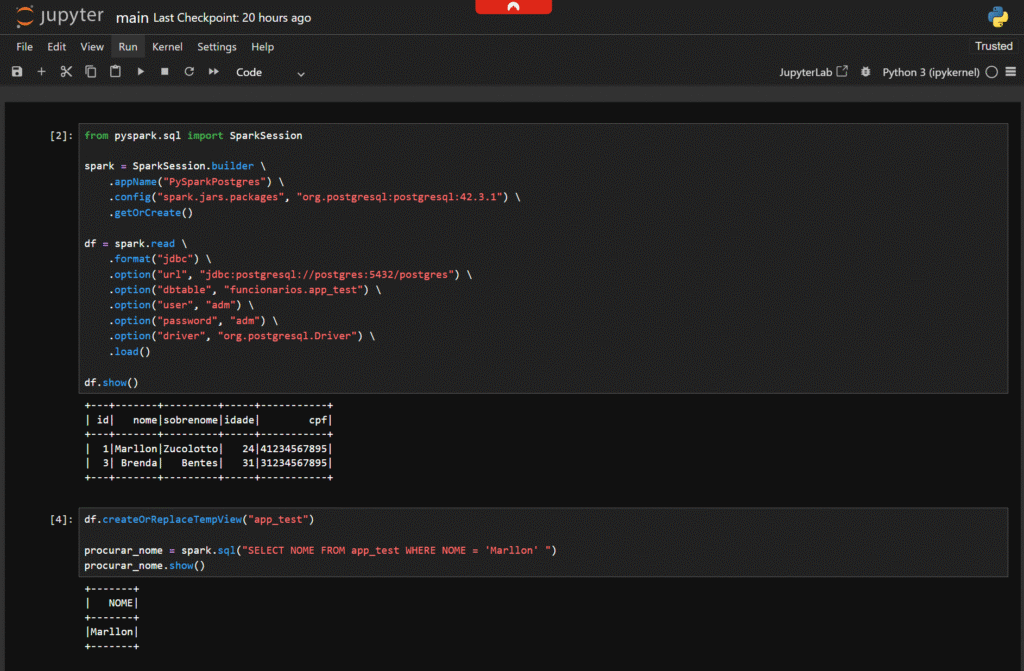
O código acima conecta o PySpark ao banco de dados PostgreSQL usando JDBC. Ele cria uma sessão do Spark e lê dados de uma tabela específica no banco. É essencial que o driver JDBC correto esteja configurado para garantir que a conexão funcione corretamente. Uma vez conectado, você pode realizar operações de leitura e escrita no banco de dados através do PySpark ou SparkSQL, explorando grandes volumes de dados de forma eficiente.
É essencial ajustar as credenciais e os nomes das tabelas conforme o seu ambiente e para proteger a segurança dos dados. Recomenda-se explorar recursos avançados do PostgreSQL, como a criação de índices e visualizações, para melhorar o desempenho das consultas. Lembre-se de que a senha, o usuário e a tabela atualmente estão definidos como adm (senha e usuário), e o esquema + tabela como funcionarios.app_test. Embora tenha seguido esse padrão, é possível conectar-se ao banco de dados por meio de plataformas como o DBevear, criar a tabela dentro do mesmo(se não souber como, veja o arquivo main_postgres.sql dentro do repositório desse projeto no meu GitHub) e, em seguida, realizar a consulta no Jupyter Notebook.
O link desses arquivos, e também os comandos SQL para criar a tabela, inserir dados, e etc, se encontram no meu GitHub.
Faça um clone do meu projeto, faça na sua máquina o passo a passo e me conte aqui nos comentários se deu tudo certo com você também. Feedbacks são sempre bem-vindos e ajudam a comunidade a crescer. Além disso, sinta-se à vontade para compartilhar suas experiências e dúvidas, pois isso pode enriquecer a discussão e ajudar outros leitores a superar os desafios que você enfrentou.
Compartilhe:







Publicar comentário